


The urgent need for a new storage operating system
An excerpt from The Holon Data Report, Part 5
The world’s operating system for data storage and retrieval is archaic due to the system’s reliance on location-based addressing. This system is enormously inefficient both in terms of energy usage and usability.
Location-based addressing
Today, the World Wide Web (www) relies upon a data storage operating system that identifies data using location-based addressing.
The http:// or https:// at the beginning of an internet website address represents a specific server in a specific data centre somewhere in the world. This is shown in Figure 1, where multiple devices (laptop, mobile phone, etc.) of clients who may be located in different geographic locations will all send a search request back to the same server location.
Figure 1: Location based addressing
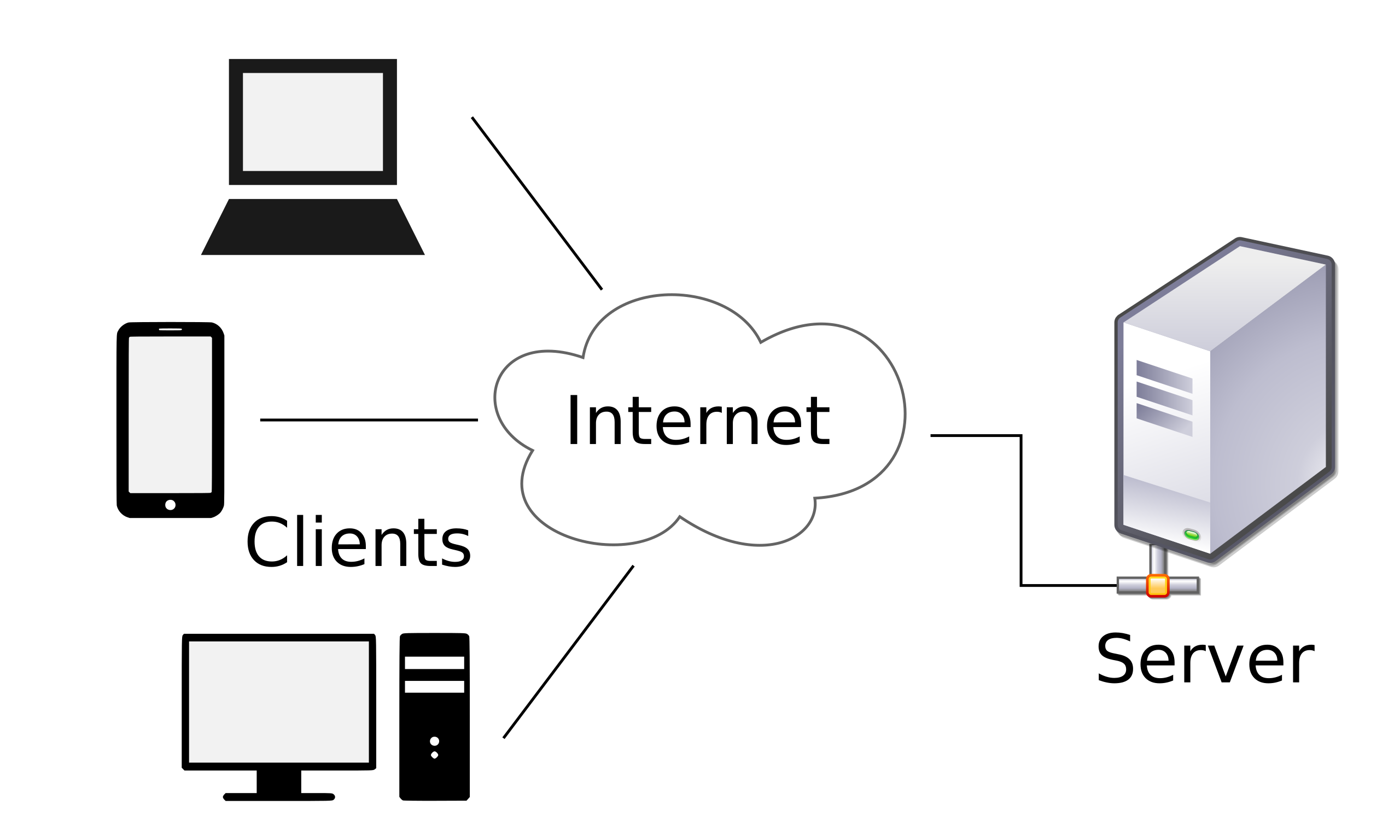
Source: airtrace.io
Unfortunately, when the World Wide Web was first established back in the 1980s, no allowances were made that would alter the web search address if the server address was changed. This means that each request would run into a dead end and the requested web page search could not be found. Many refer to this as ‘link rot’ today. According to the internet archivist site awesomenear.com, the average age of a webpage today is just 100 days. This means that too often, time and energy are wasted searching for webpages that no longer exist, often due to the fact the server’s address has changed.
Protocol Labs’ founder Juan Benet, also the founder of the InterPlanetary File System (IPFS) and Filecoin explains the significant problems with location based addressing with the following example:
‘Think of a single book you might need for work. You do not know the specific name of the book or its subject matter. The only information that you do know is that it is in the New York State Library on the 4th floor, the 3rd bookshelf from the stairs, 3rd row from the bottom, and finally the 2nd book from the left. To locate this book, you must travel to New York, go to the state library, climb the stairs, find the correct bookshelf and the correct row, only to find out that the book is no longer there.’
‘Using the same example above, if the book had instead been shifted to the 2nd row from the bottom or even the 3rd book from the left on the same floor of the New York library, the slight shift in its location means you will never be able to find it at the same address again. If we take things one dimension further, the book in the above example was sitting on your work colleagues’ desk, the limitations of location addressing only provide information as to its location at the time you received the address.’
Content-based addressing
An alternate approach to storing and accessing content is called content-based addressing. Instead of addressing content based on the geographic location where it is stored, content-based addressing creates an individual ‘hash’ for each file of data. A hash is a digital signature based on the specific content contained in the file (the ones and zeros that make it up), with the hash remaining the same, no matter where the server holding it resides.
An alternate data storage operating system to HTTP, the aforementioned IPFS, released in 2015, uses the content-based addressing approach, which can deliver a cheaper, faster (lower latency) and more secure data storage and retrieval system than the location-based addressing system currently in place today.
How does the content based addressing network work?
Protocol labs explains:
With content-based addressing, if one household requests the content, it will be temporarily stored on its device, allowing a second neighbour to retrieve the same piece of content from the closest available source which is the first neighbour’s own device.
With content-based addressing, content has a unique identifier, similar to that of an individual banknote, Users request information based specifically about its content, rather than a single address where it is located. If any alterations are made to any individual copy of a piece of content, a new unique identifier is automatically created for the altered copy (creating a new piece). This ensures the authenticity of each piece of content created and protects the owner of the first document with the safety of always being able to return to the original file address regardless of any attempted changes to their data.
In simpler terms, we move from requesting data across the internet by re-framing the question in a slightly different way (Figure 2).
Figure 2: HTTP vs. IPFS
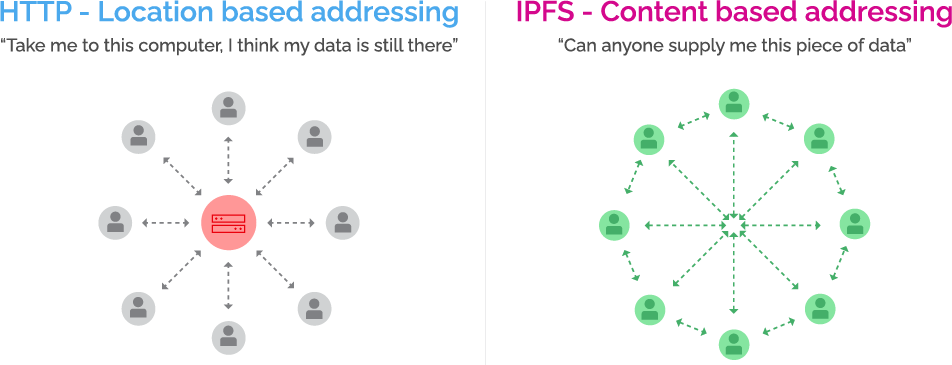 Source: Holon
Source: Holon
The Holon Data Report Part 5, in its entirety, can be found here.
Disclaimer: This Article has been prepared by Holon Global Investments Limited ABN 60 129 237 592. Holon Global Innovations Pty Ltd (“HGI”) is a wholly owned subsidiary of Holon Global Investments Limited (together “Holon”). HGI is a Filecoin (FIL) Storage Provider and is positioned as a major player in the FIL decentralised data storage arena. FIL Storage Providers are rewarded in FIL for the provision of data storage capacity. Holon, its officers, employees and agents believe that the information in this material and the sources on which the information is based (which may be sourced from third parties) are correct as at the date of publication. While every care has been taken in the preparation of this material, no warranty of accuracy or reliability is given and no responsibility for this information is accepted by Holon, its officers, employees or agents. Except where contrary to law, Holon excludes all liability for this information.





